Deep Learning bringt Mehrwert für Videolösungen
07.05.2019 - Die Entwicklung von künstlicher Intelligenz und Bilderkennung verläuft so dramatisch schnell, dass Altmeister dieser Technologien, wie Computerwissenschaftler Yann LeCun, Arbeiten ...
-
 Fortschritte beim Deep Learning von künstlicher Intelligenz sorgen dafür, dass diese Technologien für die Mehrheit der Videoüberwachungsanlagen bald eingesetzt werden könnten.
Fortschritte beim Deep Learning von künstlicher Intelligenz sorgen dafür, dass diese Technologien für die Mehrheit der Videoüberwachungsanlagen bald eingesetzt werden könnten. -

-
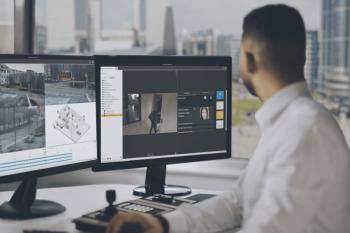
 Deep learning.PNG
Deep learning.PNG
Die Entwicklung von künstlicher Intelligenz und Bilderkennung verläuft so dramatisch schnell, dass Altmeister dieser Technologien, wie Computerwissenschaftler Yann LeCun, Arbeiten in diesen Bereichen von vor 2012 scherzhaft als ‚prähistorisch‘ bezeichnen. Die damals verfügbaren Algorithmen für die Objekterkennung waren nur zu 75 Prozent korrekt. Heute kann dank des Deep-Learning-Ansatzes eine viel höhere Genauigkeit erwartet werden. Tatsächlich bedeuten die Fortschritte der letzten 12 Monate, dass wir es ernsthaft in Betracht ziehen können, diese Technologien für die Mehrheit der Videoüberwachungsanlagen einzusetzen.
Deep Learning sollte nicht als eine erweiterte Videoanalyse-Softwareplattform gesehen werden, da die Technologie einen Paradigmenwechsel in der Sicherheitsbranche hinsichtlich der Vorfallserkennung und -reaktion repräsentiert.
Was ist Deep Learning?
Im Gegensatz zu den meisten Arten der Videoanalyse braucht ein Entwickler für Deep-Learning-Anwendungen keine komplizierten Algorithmen für die Objekterkennung zu schreiben. Stattdessen lernen Deep-Learning-Lösungen von Beispielen. Während der ersten Lernphase wird der Anwendung eine große Datenmenge gespeist, die richtig gelöste Beispiele der aktuellen Herausforderung repräsentieren, z. B. Klassifizieren einer Person nach Alter oder Geschlecht.
Ein neuronales Netz analysiert die Beziehung zwischen den eingegangenen Daten und den erwarteten Ausgabedaten, wie das Geschlecht einer Person, und lernt das Problem anhand von Analogien zu lösen. Zum Beispiel muss, damit das Geschlecht einer Person richtig erkannt werden kann, ein KI-Experte ein neuronales Netzwerk entwickeln, trainieren und validieren. Für die Lernphase wird eine Datenbank an Millionen ausgewählten und geeigneten Gesichtern, die alle mit dem bekannten, wahren Geschlecht gekennzeichnet sind, eingesetzt. Nach einigen Tagen des Lernens ist das neuronale Netzwerk einsatzbereit und wird wahrscheinlich eine Genauigkeit von circa 98 Prozent liefern. Dies entspricht in etwa der Fähigkeit von Menschen, die gleiche Entscheidung richtig zu treffen.
Die Herausforderung
Deep Learning erfordert die Fachkenntnisse eines Experten für maschinelles Lernen und massive Computerressourcen, da die Anwendung Bedingungen wie sich ändernde Lichtverhältnisse, Schatten und die Position eines Gesichts handhaben muss. Folglich müssen erweiterte Deep-Learning-Lösungen auf Servern mit angemessener Rechnerleistung und ausreichend Speicher ausgeführt werden. Damit Deep Learning zu einer sinnvollen Ergänzung der meisten Videoüberwachungsanlagen werden kann, ist eine optimierte Softwarearchitektur erforderlich, so dass die Anwendung auf den Kameras selbst ausgeführt werden kann, ähnlich wie Apps auf einem Smartphone oder Tablet.
Die Hanwha Techwin Partnerschaft
Die für Deep Learning erforderliche Verarbeitungsleistung so weit zu verringern, dass es auf den Kameras selbst ausgeführt werden kann, ist ein beachtliches Unterfangen. Deshalb verfechtet Hanwha Techwin die enge Zusammenarbeit zwischen Herstellern von Videoüberwachungslösungen und Experten dieses Spezialbereiches, um auf die aktuellsten Innovationen und Forschungserkenntnisse zugreifen zu können.
Für Hanwha Techwin bedeutet dies eine Zusammenarbeit mit A.I. Tech – eine Ausgliederung des Fachbereichs Computertechnik DIEM der Universität Salerno (UNISA) – mit einer speziellen Lab-Forschungsgruppe namens Intelligente Maschinen für die Videoerkennung. A.I. Techs CEO, Mario Vento, ist aufgeführt als einer der besten italienischen Ingenieurwissenschaftler und zählt zu den am meisten zitierten Autoren in Italien in den Bereichen künstliche Intelligenz und Bilderkennung.
K.I.-Kameras
Darüber hinaus bereitet Hanwha Techwin die Markteinführung neuer Wisenet-Kameras für die zweite Hälfte des Jahres vor. Diese werden für die Ausführung von Deep-Learning-Anwendungen direkt auf den Kameras einen Chipsatz zur Bilderkennung enthalten. Diese neuen 4K-Kameras mit 8-MP-Auflösung werden als Teil der Wisenet-Premium-Kameraserie zunächst die bereits angebotenen Videoanalysefunktionen verfeinern. Darüber hinaus werden sie Technologiepartnern eine Plattform für die Einführung von bahnbrechenden Deep-Learning-Anwendungen bieten, die über die Programmierschnittstellen (APIs) nahtlos in die neuen Kameras integriert werden können.
Weiterführende Informationen
Mehr zu AI-Lösungen von Hanwha Techwin